Confidence Interval Testing Hypothesis Testing CI example done as Hyp Test Another Hyp Test Example P-value One Tail One Tail Example
Suppose we want to do a study of whether the female students at the national campus gain body fat with age during their years at COM-FSM. Suppose we already know that the population mean body fat percentage for the new freshmen females 18 and 19 years old is µ = 25.4.
x We round up n = 12 female students at the national campus who are 21 years old and older and determine that their sample mean body fat percentage is x = 30.5 percent with a sample standard deviation of sx = 8.7.
Can we conclude that the female students at the national campus gain body fat as they age during their years at the College?
Not necessarily. Samples taken from a population with a population mean of µ = 25.4 will not necessarily have a sample mean of 25.4. If we take many different samples from the population, the sample means will distribute normally about the population mean, but each individual mean is likely to be different than the population mean.
In other words, we have to consider what the likelihood of drawing a sample that is 30.5 - 25.4 = 5.1 units away from the population mean for a sample size of 12. If we knew more about the population distribution we might be able to determine the likelihood of a 12 element sample being drawn from the population with a mean of 30.5.
In this case we know more about our sample, so we turn the problem inside out and construct a confidence interval for the likely population mean for the sample students.
If this confidence interval includes the known population mean for the 18 to 19 years olds, then we cannot rule out the possibility that our 12 student sample is from that same population. In this instance we cannot conclude that the women gain body fat.
If the confidence interval does NOT include the known population mean for the 18 to 19 year old students then we can say that the older students come from a different population: a population with a higher population mean body fat. In this instance we can conclude that the older women have a different and probably higher body fat level.
One of the decisions we obviously have to make is the level of confidence we will use in the problem. Here we enter a contentious area. The level of confidence we choose, our level of bravery or temerity, will determine whether or not we conclude that the older females have a different body fat content. For a detailed if somewhat advanced discussion of this issue see The Fallacy of the Null-Hypothesis Significance Test by William Rozeboom.
In education and the social sciences there is a tradition of using a 95% confidence interval. In some fields three different confidence intervals are reported, typically a 90%, 95%, and 99% confidence interval. Why not use a 100% confidence interval? The normal and t-distributions are asymptotic to the x-axis. A 100% confidence interval would run to plus and minus infinity. We can never be 100% confident.
In the above example a 95% confidence interval would be calculated in the following way:
n = 12
x = 30.53
sx = 8.67
c = 0.95
degrees of freedom = 12 -1 = 11
tc = tinv((1-0.95,11) = 2.20
E = tc*sx/sqrt(12) = 5.51
x - E < m <
![]() + E
+ E
25.02 < m < 36.04
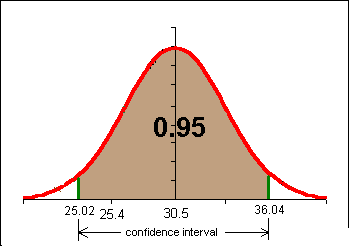
The 95% confidence interval for our n = 12 sample includes the population mean 25.3. We CANNOT conclude at the 95% confidence level that this sample DID NOT come from a population with a population mean µ of 25.3.
Another way of thinking of this is to say that 30.5 is not sufficiently separated from 25.8 for the difference to be statistically significant at a confidence level of 95% in the above example.
In common language, the women are not gaining body fat.
The above process is reduced to a formulaic structure in hypothesis testing. Hypothesis testing is the process of determining whether a confidence interval includes a previously known population mean value. If the population mean value is included, then we do not have a statistically significant result. If the mean is not encompassed by the confidence interval, then we have a statistically significant result to report.
Homework
If I expand my study of female students 21+ to n=24 and find a sample mean ![]() =28.7 and an sx=7, is the new sample mean
statistically significantly different from a population mean µ of 25.4 at a confidence
level of c = 0.90?
=28.7 and an sx=7, is the new sample mean
statistically significantly different from a population mean µ of 25.4 at a confidence
level of c = 0.90?
The null hypothesis is the supposition that there is no change in a value from some pre-existing, historical, or expected value. The null hypothesis literally supposes that the change is null, non-existent, that there is no change.
In the previous example the null hypothesis would have been H0: µ = 25.4
The alternate hypothesis is the supposition that there is a change in the value from some pre-existing, historical, or expected value. The symbols "<>" mean "does not equal."
H1: µ <> 25.4
We run hypothesis test to determine if new data confirms or rejects the null hypothesis.
If the new data falls within the confidence interval, then the new data does not contradict the null hypothesis. In this instance we say that "we fail to reject the null hypothesis." Note that we do not actually affirm the null hypothesis. This is really little more than semantic shenanigans that statisticians use to protect their derriers. Although we run around saying we failed to reject the null hypothesis, in practice it means we left the null hypothesis standing: we de facto accepted the null hypothesis.
If the new data falls outside the confidence interval, then the new data would cause us to reject the null hypothesis. In this instance we say "we reject the null hypothesis." Note that we never say that we accept the alternate hypothesis.
In our example above we failed to reject the null hypothesis H0 that the population mean for the older students was 25.4, the same population mean as the younger students.
In the example above a 95% confidence interval was used. At this point in your statistical development and this course you can think of this as a 5% chance we have reached the wrong conclusion.
Imagine that the 18 to 19 year old students had a body fat percentage of 24 in the previous example. We would have rejected the null hypothesis and said that the older students have a different and probably larger body fat percentage.
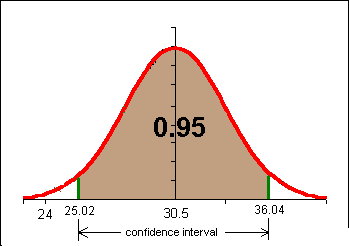
There is, however, a small probability (less than 5%) that a 12 element sample with a mean of 30.5 and a standard deviation of 8.7 could come from a population with a population mean of 24. This risk of rejecting the null hypothesis when we should not reject it is called alpha a. Alpha is 1-confidence level, or a = 1-c. In hypothesis testing we use a instead of the confidence level c.
| Suppose | And we accept H0 as true | Reject H0 as false |
|---|---|---|
| H0 is true | Correct decision. Probability: 1-a | Type I error. Probability: a |
| H0 is false | Type II error. Probability: b | Correct decision. |
Hypothesis testing seeks to control alpha a. We cannot determine b (beta) with the statistical tools you learn in this course.
Alpha a is called the level of significance. 1-b is called the "power" of the test.
The regions beyond the confidence interval are called the "tails" or critical regions of the test. In the above example there are two tails each with an area of 0.025. Alpha a = 0.05
For hypothesis testing it is simply safest to always use the t-distribution. In the example further below we will run a two-tail test.
Steps
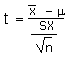
Example
Using the data from the first section of these notes:
=
(30.53-25.4)/(8.67/sqrt(8.67)) = 2.05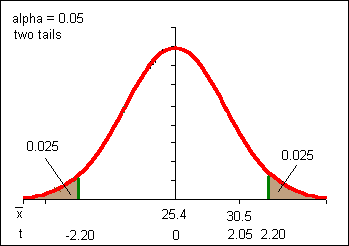
Note the changes in the above sketch from the confidence interval work. Now the distribution is centered on µ with the distribution curve described by a t-distribution with eleven degrees of freedom. In our confidence interval work we centered our t-distribution on the sample mean. The result is, however, the same due to the symmetry of the problems and the curve. If our distribution were not symmetric we could not perform this sleight of hand.
I have a previously known population mean m running pace of 6'09" (6.15). In 2001 I've been too busy to run regularly. On my five most recent runs I've averaged a 6'23" (6.38) pace with a standard deviation 1'00" At an alpha a=0.05, am I really running differently this year?
H0: µ = 6.15
H1: µ <> 6.15
Pay close attention to the above! We DO NOT write H1: µ = 6.23. This is a common beginning mistake.
=
(6.38-6.15)/(1.00/sqrt(5)) = 0.51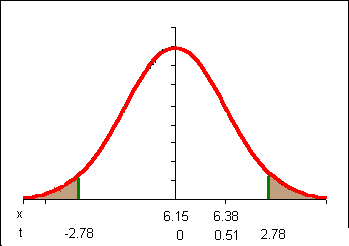
Note that in my sketch I am centering my distribution on the population mean and looking at the distribution of sample means for sample sizes of 5 based on that population mean. Then I look at where my actual sample mean falls with respect to that distribution.
Note that my t-statistic does not fall "beyond" the critical values. I do not have enough separation from my population mean: I cannot reject H0. So I fail to reject H0. I am not performing differently than last year. The implication is that I am not slower.
In modern practice we also do one tailed tests: we presume our alternate hypothesis is specifically larger or smaller than the null hypothesis value. This leads to one-tailed tests. These are popular with researchers because they increase the probability of rejecting the null hypothesis (which is what most researchers are hoping to do). Some statisticians recommend against ever using one-tailed tests exactly because they increase the probability of a type I error.
The text and the real world do use one-tailed tests. Suppose I decide I want to test to see if I am not just performing differently, but am actually slower. Then I can do a one tail test at the 95% confidence level. Here alpha will again be 0.05. In order to put all of the area into one tail I will have to use the Excel function TINV(2*a,df).
H0: m = 6.15
H1: m < 6.15
m=6.15
x=6.38
sx = 1.00
n=5
degrees of freedom (df)=4
tc = TINV(2*a,df) = TINV(2*0.05,4) = 2.13
t-statistic = =
(6.38-6.15)/(1.00/sqrt(5)) = 0.51
Note that the t-statistic calculation is unaffected by this change in the problem.
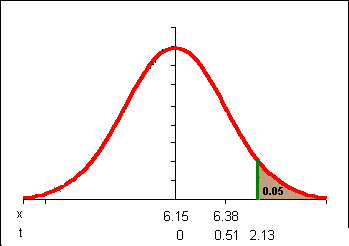
Note that my t-statistic would have to exceed only 2.13 instead of 2.78 in order to achieve statistical significance. Still, 0.51 is not beyond 2.13 so I still DO NOT reject the null hypothesis. I am not really slower, not based on this data.
Kosrae High School:
TOEFL
m = 477
x (2001) = 460
n = 96
sx = 60
At a=0.01, stat sig diff?
Return to our first example in these notes where the body fat percentage of 12 female
students 21 years old and older was ![]() =30.53
with a standard deviation sx=8.67 was tested against a null hypothesis H0 that
the population mean body fat for 18 to 19 year old students was µ=25.4. We failed to
reject the null hypothesis at an alpha of 0.05. What if we are willing to take a larger
risk? What if we are willing to risk a type I error rate of 10%? This would be an alpha of
0.10.
=30.53
with a standard deviation sx=8.67 was tested against a null hypothesis H0 that
the population mean body fat for 18 to 19 year old students was µ=25.4. We failed to
reject the null hypothesis at an alpha of 0.05. What if we are willing to take a larger
risk? What if we are willing to risk a type I error rate of 10%? This would be an alpha of
0.10.
=
(30.53-25.4)/(8.67/sqrt(8.67)) = 2.05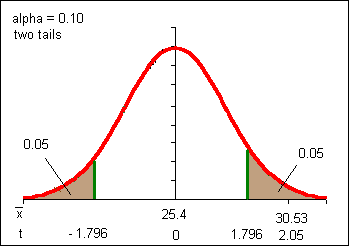
With an alpha of 0.10 (a confidence interval of 0.90) our results are statistically significant. These same results were NOT statistically significant at an alpha a of 0.05. So which is correct:
Note how we would have said this in confidence interval language:
The answer is that it depends on how much risk you are willing take, a 5% chance of committing a Type I error (rejecting a null hypothesis that is true) or a larger 10% chance of committing a Type I error. The result depends on your own personal level of aversity to risk. That's a heck of a mathematical mess: the answer depends on your personal willingness to take a particular risk.
Consider what happens if someone decides they only want to be wrong 1 in 15 times: that corresponds to an alpha of a=0.067. They cannot use either of the above examples to decide whether to reject the null hypothesis. We need a system to indicate the boundary at which alpha changes from failure to reject the null hypothesis to rejection of the null hypothesis.
Consider what it would mean if t-critical were equal to the t-statistic. The alpha at which t-critical equals the t-statistic would be that boundary value for alpha a. We will call that boundary value p.
p is the alpha for which tinv(a,df)=. But how to solve for a?
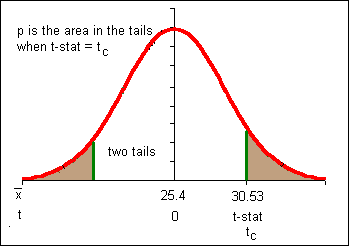
The solution is to calculate the area in the tails under the t-distribution using the tdist function.
p = TDIST(ABS(t-statistic),degrees of freedom,number of tails)
Note that TDIST can only handle positive values for the t-statistic, hence the absolute value function.
p = TDIST(ABS(2.05,11,2) = 0.06501
The p value represents the SMALLEST alpha for which the test is statistically significant.
The p value is the SMALLEST alpha for which we reject the null hypothesis.
Thus for all alpha greater than 0.065 we reject the null hypothesis. The "one in fifteen" person would reject the null hypothesis (0.0667 > 0.065). The alpha = 0.05 person would not reject the null hypothesis.
If the pre-chosen alpha is more than p, then we reject the null hypothesis. If the pre-chosen alpha is less than p, then we fail to reject the null hypothesis.
The p value lets each person decide on their own level of risk and removes the arbitrariness of personal risk choices.
Because many studies in education and the social sciences are done at an alpha of 0.05, a p value at or below 0.05 is used to reject the null hypothesis.
1-p is the confidence interval for which the new value does not include the pre-existing population mean.
Note:
p = tdist(abs(tstat),df,tails)
All of work above in confidence intervals and hypothesis testing has been with two-tailed confidence intervals and two-tailed hypothesis tests. There are statisticians who feel one should never leave the realm of two-tailed intervals and tests.
Unfortunately, the practice by scientists, business, educators and many of the fields in social science, is to use one-tailed tests when one is fairly certain that the sample has changed in a particular direction. The effect of moving to one tailed test is to increase one's risk of committing a Type I error.
One tailed tests are identical to two-tailed tests except the formula for tc is TINV(2*a,df) and the formula for p is TDIST(ABS(tstat),df,1).
Suppose we decide that the 30.53 body fat percentage for females 21+ at the College definitely represents an increase. We could opt to run a one tailed test at an alpha of 0.05.
=
(30.53-25.4)/(8.67/sqrt(8.67)) = 2.05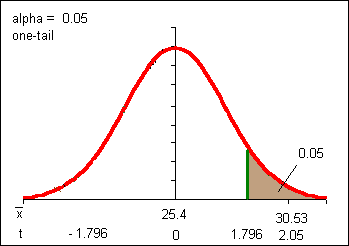
This result should look familiar: it is the result of the two tail test at alpha = 0.10, only now we are claiming we have halved the Type I error rate (a) to 0.05. Some statisticians object to this saying we are attempting to artificially reduce our Type I error rate by pre-deciding the direction of the change. Either that or we are making a post-hoc decision based on the experimental results. Either way we are allowing assumptions into an otherwise mathematical process. Allowing personal decisions into the process, including those involving a, always involve some controversy in the field of statistics.
=TDIST(0.51,4,2) = 0.64
| Statistic or Parameter | Symbol | Equations | Excel |
|---|---|---|---|
| Basic Statistics | |||
| Square root | Ö | =SQRT(number) | |
| Sample size | n | =COUNT(data) | |
| Sample mean | x | Sx/n | =AVERAGE(data) |
| Sample standard deviation | sx | =STDEV(data) | |
| Sample Coefficient of Variation | CV | 100(sx/x) | =100*STDEV(data)/AVERAGE(data) |
| Linear Regression | |||
| Slope | b | =SLOPE(y data, x data) | |
| Intercept | a | =INTERCEPT(y data, x data) | |
| Correlation | r | =CORREL(y data, x data) | |
| Coefficient of Determination | r² | =(CORREL(y data, x data))^2 | |
| Normal Statistics | |||
| Calculate a z value from an x | z | = |
=STANDARDIZE(x, m, s) |
| Calculate an x value from a z | x | = s z + m | = s*z+m |
| Calculate a z value from an x | z | 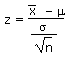 |
|
| Calculate an x from a z | =m + zc*sx/sqrt(n) | ||
| Find a probability p from a z value | =NORMSDIST(z) | ||
| Find a z value from a probability p | =NORMSINV(p) | ||
| Confidence interval statistics | |||
| Degrees of freedom | df | = n-1 | |
| Find a zc value from a confidence level c | zc | =ABS(NORMSINV((1-c)/2)) | |
| Find a tc value from a confidence level c | tc | =TINV(1-c,df) | |
| Calculate an error tolerance E of a mean for n ³ 30 using sx | E | =zc*sx/SQRT(n) | |
| Calculate an error tolerance E of a mean for n < 30 using sx. Can also be used for n ³ 30. | E | =tc*sx/SQRT(n) | |
| Calculate a confidence interval for a population mean m from a sample mean x and an error tolerance E | x-E< m <x+E | ||
| Hypothesis Testing | |||
| Calculate a t-statistic (tstat) | t | |
|
| Calculate t-critical for a two-tailed test | tc | =TINV(a,df) | |
| Calculate t-critical for a one-tailed test | tc | =TINV(2*a,df) | |
| Calculate a p-value from a t-statistic | p | = TDIST(ABS(tstat),df,#tails) | |
Statistics home Lee Ling home COM-FSM home page