| Class Upper Limit x |
Frequency | Relative Frequency P(x) |
x*P(x) | (x - m)²P(x) |
|---|---|---|---|---|
| 270 | 1 | _____________ |
||
| 310 | 41 | _____________ |
||
| 350 | 138 | _____________ |
||
| 390 | 189 | _____________ |
||
| 430 | 204 | _____________ |
||
| 470 | 242 | _____________ |
||
| 510 | 188 | _____________ |
||
| 550 | 117 | _____________ |
||
| 590 | 66 | _____________ |
||
| 630 | 19 | _____________ |
||
| 670 | 8 | _____________ |
||
Sum: |
________ |
_____________ |
______ |
________ |
Sqrt: |
________ |
- Calculate the relative frequencies P(x) and record the relative frequencies in the table
above.
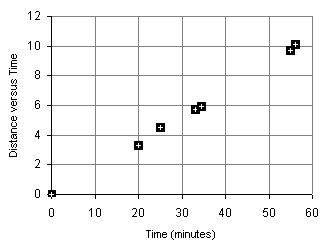
- Sketch a relative frequency histogram of the data, labeling your horizontal and vertical
axes as appropriate.
- What is the shape of the distribution? _____
- Calculate the mean for the TOEFL data by summing the x*P(x) values. You do NOT
need to record each x*P(x) value in the table above: use Excel to do your work. You
need only write down the value of the mean that you calculate.
mean m = _________________
- Calculate the standard deviation for the TOEFL data by calculating
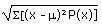 . You do
NOT need to record each (x - m)²P(x) value in the table above: use Excel to do your
work. You need only write down the value of the standard deviation that you
calculate.
. You do
NOT need to record each (x - m)²P(x) value in the table above: use Excel to do your
work. You need only write down the value of the standard deviation that you
calculate.
standard deviation s =
- Determine the probability of a TOEFL score being between 311 and 350, P(311-350) =
______________
- Find the mean of the data given.___________
- Use the mean and standard deviation from above to calculate a coefficient of variation
for the data.
coeffiecient of variation = _____________
- What is the value of n for this data set? _____________